
发布日期:2022-10-09 点击率:98
AlphaGo(阿尔法狗)战胜了柯洁,人工智能赢了,赢家仍然是人类!
之前介绍过深度强化学习DRL,其中一个最最经典的应用就是谷歌DeepMind团队研发的围棋程序AlphaGo(阿尔法狗)。AlphaGo的胜利将深度强化学习推上新的热点和高度,成为AI人工智能历史上一个新的里程碑。

有必要跟大家一起探讨一下AlphaGo(阿尔法狗),了解一下AlphaGo背后神奇的AI力量。
围棋的程序设计:

围棋是一个完美的、有趣的数学问题。
围棋棋盘是19x19路,所以一共是361个交叉点,每个交叉点有三种状态,可以用1表示黑子,-1表示白字,0表示无子,考虑到每个位置还可能有落子的时间、这个位置的气等其他信息,可以用一个361 * n维的向量来表示一个棋盘的状态。则把一个棋盘状态向量记为s。
当状态s下,暂时不考虑无法落子的地方,可供下一步落子的空间也是361个。把下一步的落子的行动也用361维的向量来表示记为a。
于是,设计一个围棋人工智能的程序,就转变为:任意给定一个s状态,寻找最好的应对策略a,让程序按照这个策略走,最后获得棋盘上最大的地盘。

谷歌DeepMind的围棋程序AlphaGo(阿尔法狗)就是基于这样思想设计的。
AlphaGo概述:
AlphaGo(阿尔法狗)创新性地将深度强化学习DRL和蒙特卡罗树搜索MCTS相结合, 通过价值网络(value network)评估局面以减小搜索深度, 利用策略网络(policy network)降低搜索宽度, 使搜索效率得到大幅提升, 胜率估算也更加精确。
MCTS必要性:
AlphaGo(阿尔法狗)系统中除了深度强化学习DRL外,为什么还需要蒙特卡罗树搜索?
围棋棋面总共有19 * 19 = 361个落子位置。假如计算机有足够的计算能力,理论上来说,可以穷举黑白双方所有可能的落子位置,找到最优或次优落子策略。如果穷举黑白双方所有可能的落子位置,各种组合的总数,大约是 250^150 数量级,即围棋的计算复杂度约为250的150次方。假如采用传统的暴力搜索方式(遍历搜索方式),用当今世界最强大云计算系统,算几十年也算不完。按照现有的计算能力是远远无法解决围棋问题的。早期计算机围棋软件通过专家系统和模糊匹配缩小搜索空间, 减轻计算强度, 但受限于计算资源和硬件能力, 实际效果并不理想。
但是到了2006年,蒙特卡罗树搜索的应用标志着计算机围棋进入了崭新阶段。
AlphaGo网络结构:
网络结构如下图所示:
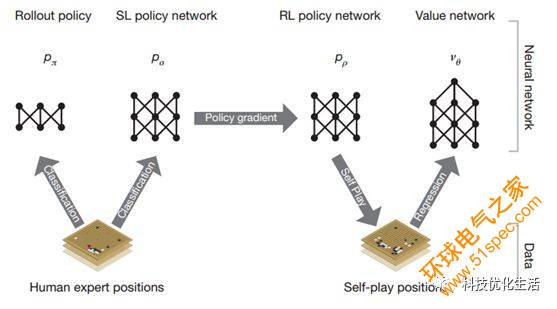
AlphaGo系统组成:
AlphaGo(阿尔法狗)系统主要由几个部分组成:
1.策略网络(Policy Network):给定当前围棋局面,预测/采样下一步的走棋。
2.快速走子(Fast rollout):目标和策略网络一样,只不过围棋有时间限制,需要在规定时间内适当牺牲走棋质量情况下,快速落子,速度要比策略网络要快1000倍。
3.价值网络(Value Network):给定当前围棋局面,估计是白胜还是黑胜。
4.蒙特卡罗树搜索(Monte Carlo Tree Search):不穷举所有组合,找到最优或次优位置。
把以上这四个部分结合起来,形成一个完整的AlphaGo(阿尔法狗)系统。
蒙特卡洛树搜索 (MCTS) 是一个大框架,许多博弈AI都会采用这个框架。强化学习(RL)是学习方法,用来提升AI的实力。深度学习(DL)采用了深度神经网络 (DNN),它是工具,用来拟合围棋局面评估函数和策略函数的。蒙特卡洛树搜索 (MCTS) 和强化学习RL让具有自学能力、并行的围棋博弈算法成为可能。深度学习(DL)让量化地评估围棋局面成为了可能。

小结:
可以说 AlphaGo 最大优势就是它应用了通用算法,而不是仅局限于围棋领域的算法。AlphaGo胜利证明了像围棋这样复杂的问题,都可以通过先进的AI人工智能技术来解决。
下一篇: PLC、DCS、FCS三大控
上一篇: 索尔维全系列Solef?PV


