发布日期:2022-04-25 点击率:32
GPU – 加速计算是数据从业者和企业的游戏规则改变者,但利用 GPU 对数据专业人士来说可能是一项挑战。RAPIDS通过熟悉的界面抽象加速数据科学的复杂性,从而解决了这些挑战。使用 RAPIDS 时,从业者可以快速加速 NVIDIA GPU 上的数据科学工作负载,将数据加载、处理和培训等操作从数小时减少到数秒。
管理大规模数据科学基础设施带来了重大挑战。有了 Saturn 云,管理基于 GPU 的基础设施变得更加容易,使从业者和企业能够专注于解决其业务挑战。
什么是 Saturn Cloud ?
Saturn Cloud 是一个端到端平台,可通过云中的可扩展计算资源访问基于 Python 的数据科学。 Saturn Cloud 为移动到云提供了一条简单的路径,无需成本、设置或基础设施工作。这包括使用预构建的环境访问配备 GPU 的计算资源,预构建的环境包括 RAPIDS 、 PyTorch 和 TensorFlow 等工具。
用户可以在托管的 JupyterLab 环境中编写代码,或者使用 SSH 连接自己的 IDE (集成开发环境)。随着数据量的增加,用户可以扩展到支持 GPU 的Dask集群,以便在分布式计算机网络上执行代码。开发数据管道、模型或仪表板后,用户可以将其部署到持久位置,或创建作业以按计划运行它。
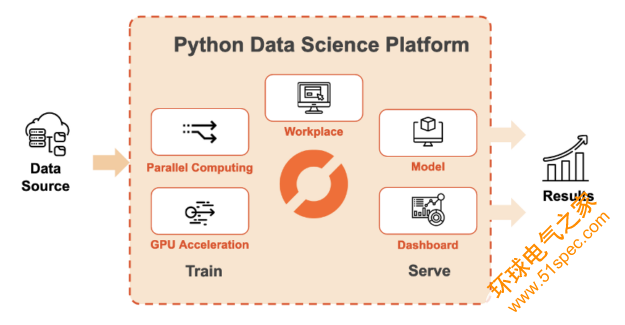
图 1 : Saturn Cloud 为大规模数据科学提供了一个基于 Python 的平台。
除了 Saturn Cloud 的企业产品外, Saturn Cloud 还提供托管产品,任何人都可以免费开始 GPU – 加速数据科学。托管免费计划每月包括 10 小时的 Jupyter 工作区和 3 小时的 Dask 集群。如果需要更多资源,可以升级到托管的 Pro plan 和现收现付。
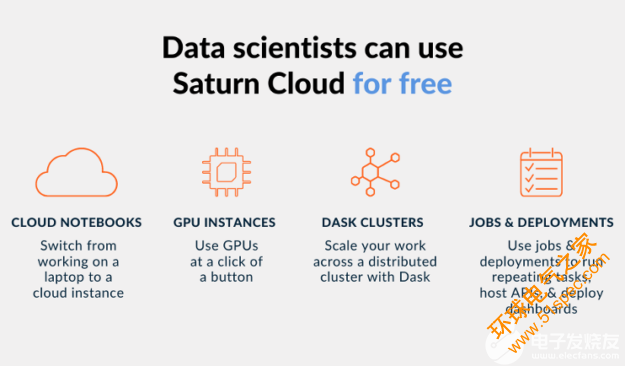
图 2 :用户可以在 Saturn 云主机上访问笔记本电脑、 GPU s 、集群和调度工具。
Saturn Cloud 为 GPU 加速数据科学应用提供了一个易于使用的平台。借助该平台, GPU 成为日常数据科学堆栈的核心组件。
开始使用 Saturn Cloud 上的 RAPIDS
在 Saturn Cloud 上创建免费帐户后,您可以快速开始使用 RAPIDS 。在本节中,我们将展示如何使用 Saturn Cloud 在纽约出租车数据上使用 RAPIDS 训练机器学习模型。然后我们进一步在 Dask 集群上运行 RAPIDS 。通过结合 RAPIDS 和 Dask ,您可以使用多节点 GPU 系统网络来训练模型,其速度远远快于使用单个 GPU 系统的速度。
在 Saturn Cloud 上创建免费帐户后,打开服务并转到“资源”页面。从那里,查看预制的资源模板,并单击标记为 RAPIDS 的模板。
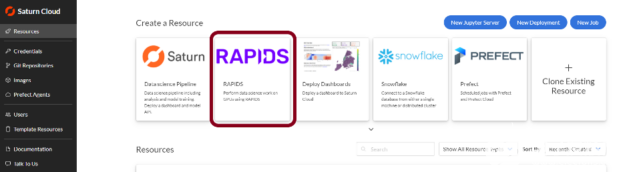
图 3 : Saturn Cloud 预先配置了 RAPIDS 图像,以便于使用 GPU s 。
您将被带到新创建的资源。这里的一切都已设置好,您可以在 GPU 硬件上运行代码, Docker 映像安装了所有必要的 Python 和 RAPIDS 软件包。
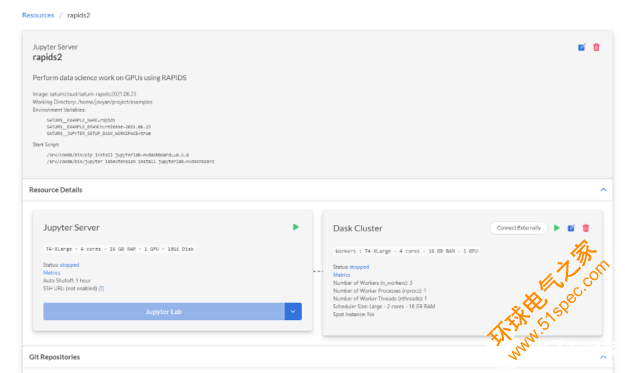
图 4 : Saturn Cloud 建立了一个装备了 RAPIDS 的 Jupyter 服务器和 Dask 集群。
开箱即用的环境包括:
4 v CPU s ,带 16 GB RAM
NVIDIA T4 GPU 16GB 的 GPU RAM
RAPIDS: including cuDF, cuML, XGBoost, 还有更多
NVDashboard JupyterLab 扩展,用于实时 GPU 指标
用于监视集群的 Dask 和Dask JupyterLab 扩展
常见的 PyData 包,如 NumPy 、 SciPy 、 pandas 和 scikit-learn
单击“ Jupyter 服务器”和“ Dask 群集”卡上的播放按钮启动资源。现在,您的集群已准备就绪;继续了解 GPU 如何显著加快模型训练时间。
图 5 :具有单个和多个 GPU 后端的预构建 RAPIDS 环境。
用 RAPIDS 训练随机森林模型
对于本练习,我们将使用纽约出租车数据集。我们将加载一个 CSV 文件,选择我们的功能,然后训练一个随机森林模型。为了说明在 GPU 上使用 RAPIDS 可以实现的运行时加速,我们将首先使用传统的基于 CPU 的 PyData 包,如 pandas 和 scikit learn 。
我们的机器学习模型回答了以下问题:
根据行程开始时已知的特征,该行程是否会导致高小费?
这里的因变量是“小费百分比”,即小费的美元金额除以乘坐成本的美元金额。我们将使用取货目的地、下车目的地和乘客数量作为自变量。
接下来,您可以将下面的代码块复制到 Saturn Cloud JupyterLab 界面中的新笔记本中。或者,您可以下载整个笔记本都在这里。首先,我们将设置一个上下文管理器来计时代码的不同部分:
from time import time
from contextlib import contextmanager
times = {}
@contextmanager
def timing(description: str) -> None:
start = time()
yield
elapsed = time() - start
times[description] = elapsed
print(f"{description}: {round(elapsed)} seconds")然后,我们将从纽约出租车 S3 存储桶中取出一个 CSV 文件。注意,我们可以将文件直接从 S3 读入数据帧。但是,我们希望将网络 IO 时间与 CPU 或 GPU 上的处理时间分开,如果我们希望在数十次修改后运行此步骤,我们就不必多次承担网络成本。
!卷曲 https :// s3 。 Amazon aws 。 com / nyc tlc / trip + data / yellow _ tripdata _ 2019-01 。 csv 》 data 。 csv
在讨论 GPU 部分之前,让我们先看看传统的 PyData 软件包(如 pandas 和使用 CPU 进行计算的 scikit )的情况。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier as RFCPU
with timing("CPU: CSV Load"):
taxi_cpu = pd.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_cpu = (
taxi_cpu[["PULocationID", "DOLocationID", "passenger_count"]]
.fillna(-1)
)
y_cpu = (taxi_cpu["tip_amount"] > 1)
rf_cpu = RFCPU(n_estimators=100, n_jobs=-1)
with timing("CPU: Random Forest"):
_ = rf_cpu.fit(X_cpu, y_cpu)CPU 代码需要几分钟的时间,因此请继续并为 GPU 代码打开一个新的笔记本。您会注意到, GPU 代码看起来几乎与 CPU 代码相同,只是我们将“ pandas ”替换为“ cuDF ”,将“ scikit learn ”替换为“ cuml ”。 RAPIDS 包有意地类似于典型的 PyData 包,使您的代码尽可能容易地在 GPU 上运行!
import cudf
from cuml.ensemble import RandomForestClassifier as RFGPU
with timing("GPU: CSV Load"):
taxi_gpu = cudf.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_gpu = (
taxi_gpu[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_gpu = (taxi_gpu["tip_amount"] > 1).astype("int32")
rf_gpu = RFGPU(n_estimators=100)
with timing("GPU: Random Forest"):
_ = rf_gpu.fit(X_gpu, y_gpu)You should have been able to copy this into a new notebook and execute the whole thing before the CPU version finished. once that’s done, check out the difference in the runtimes of each.
使用 CPU , CSV 加载耗时 13 秒,而随机森林训练耗时 364 秒( 6 分钟)。使用 GPU , CSV 加载耗时 2 秒,而随机森林训练耗时 18 秒。这就是快 7 倍 CSV 加载和快 20 倍随机林训练。

图 6 : RAPIDS + Saturn Cloud 帮助用户解决他们的挑战,而不是等待进程。
使用 RAPIDS + Dask 解决大数据问题
虽然单个 GPU 对于许多用例来说足够强大,但现代数据科学用例通常受益于越来越大的数据集,以生成更准确、更深刻的 i NSight s 。许多用例都需要由多个 GPU 或节点组成的横向扩展基础架构,以便在工作负载中快速切换。 RAPIDS 与 Dask 很好地匹配,以支持横向扩展到大型 GPU 集群。
from dask.distributed import Client, wait
from dask_saturn import SaturnCluster
import dask_cudf
from cuml.dask.ensemble import RandomForestClassifier as RFDask
cluster = SaturnCluster()
client = Client(cluster)
taxi_dask = dask_cudf.read_csv(
"s3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
storage_options={"anon": True},
assume_missing=True,
)
X_dask = (
taxi_dask[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_dask = (taxi_dask["tip_amount"] > 1).astype("int32")
X_dask, y_dask = client.persist([X_dask, y_dask])
_ = wait(X_dask)
rf_dask = RFDask(n_estimators=100)
_ = rf_dask.fit(X_dask, y_dask)使用 RAPIDS 和 Saturn Cloud 简化加速数据科学
此示例显示了在 GPU 或 GPU Dask 集群上使用 RAPIDS 加速数据科学工作负载是多么容易。使用 RAPIDS 可以将训练时间增加一个数量级,这可以帮助您更快地迭代模型。有了 Saturn Cloud ,你可以在需要的时候启动 Jupyter 笔记本电脑、 Dask 集群和其他云资源。
关于作者
Jacob Schmitt 是 NVIDIA 企业数据科学产品团队的产品营销经理,他帮助企业用户连接到强大的数据科学解决方案。在加入 NVIDIA 之前,他是 Capital One 机器学习中心的产品经理,推动了诸如 Dask 和 RAPIDS 等强大开源库的采用和扩展。
Jacqueline Nolis 博士是一位数据科学领导者,在 DSW 和 Airbnb 等公司管理数据科学团队和项目方面拥有超过 15 年的经验。她目前是 Saturn Cloud 的数据科学负责人,她帮助为数据科学家设计产品。杰奎琳有博士学位。在工业工程和合著本书建立在数据科学的职业生涯。
审核编辑:郭婷
使用 Saturn Cloud ,您可以从我们之前使用的同一项目连接到 GPU 供电的 Dask 集群。然后,要在 GPU 上使用 Dask ,您需要将cudf包替换为dask_cudf以加载数据,并使用cuml.dask子模块进行机器学习。现在请注意,我们在dask_cudf.read_csv中使用 glob 语法加载 2019 年的所有数据,而不是像以前那样加载一个月的数据。这与我们前面的示例一样处理大约12x的数据量,但只使用 GPU 集群处理90 秒。
下一篇: PLC、DCS、FCS三大控
上一篇: 四维图新旗下世纪高通


