
发布日期:2022-05-20 点击率:36
0 引言
RFID系统主要由读写器和射频卡两部分组成,它们之间可以通过无线方式进行通信。其中,射频卡中存储了需要识别、交互的数据,并且可以实时写入或擦除。RFID系统工作时,若有多个电子标签同时在同一个阅读器的作用范围内向阅读器发送数据,则往往会出现信号的干扰,这个干扰就被称为碰撞,其结果将会导致此次数据传输的失败,因而必须采用适当的技术防止碰撞。最近,有人提出了动态二进制搜索法、跳跃式类二进制搜索法等二进制防碰撞算法的改进算法。国际上广泛应用的防碰撞算法是ALOHO法和二进制搜索法及对这两种算法的改进方法,如时隙ALOHO法、动态二进制搜索法、后退式二进制法搜索等。其中,动态二进制法是国际标准所推荐的防碰撞方法。就此,本文提出了一种二进制搜索法的改进型算法。
1 二进制搜索算法
1.1 二进制搜索算法(BS)原理
二进制搜索算法又称为二叉树搜索算法。由于它要求能够在阅读器中确定数据碰撞位的准确位置,因此,必须要有合适的位编码法。曼彻斯特码用上升沿表示0,用下降沿表示1,在数据传输过程中不允许“没有改变”的状态。如果采用ASK调制方式,当多个电子标签同时发送的数据位值不同时,则对应的曼彻斯特码的上升沿和下降沿相互抵消,造成一种错误的状态,从而可以确定碰撞位置。假设有两个编码为8位的电子标签,利用曼彻斯特编码识别碰撞位的原理如图1所示。阅读器检出的碰撞位为D6位和D5位。
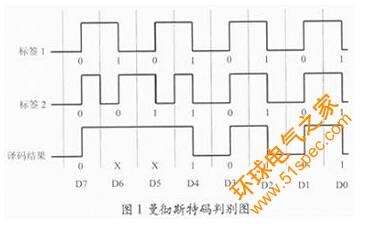
一般情况下,二进制搜索算法必须先能辨认出阅读器中数据冲突的确切位置,这一点是下面算法的基础。这里主要对以下几个命令以及原理流程进行简述:
REQUEST(某序列号Q):如果标签序列号小于或等于Q,则该标签进入识别状态,将发自己的序列号给阅读器,否则处于等待状态;
SELECT(某序列号Q):如果标签序列号等于Q,则该标签进入选中状态,否则继续等待识别;
READ:选中的标签与阅读器进行数据通信;
UNSELECT:取消前选中标签,该标签进入静默状态,待所有标签完成通信或者该标签重新入场后,才能进入等待状态。
1.2 二进制搜索算法的深入分析
阅读器和标签之间的通信次数决定了识别速度。从众多标签中识别出一个标签的平均通信次数为L。在二进制搜索算法中,我们知道:
L=log2N+1 (1)
由于二进制搜索算法的识别独立性,N个标签的全部识别平均通信次数为:
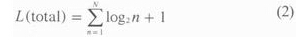
当标签数目很多的时候,由于每次独立识别浪费了大量通信次数,算法总的通信次数必然会增长很快。二进制搜索算法还有一个很明显的弱点:阅读器发送给每个标签的比较序列,其实有用的信息只包含在高于上次碰撞位X的高位之中,低于碰撞位的通信产生冗余。
2 动态二进制搜索算法
2.1 动态二进制搜索算法原理
前面所述的二进制搜索算法,每次搜索都需要完整的传输标签的序列号ID。但在实际应用中,标签的序列号长度不再像前所述那样为8位,而可能是长达10个字节甚至更大的规模。这样采用BS算法,RFID系统标签的传输量将大增,为此动态二进制搜索(DBS)算法应运而生。D BS算法是IS014443A这一国际标准所推荐的防碰撞算法。序列号ID中的全部信息对于成功识别出标签不是不可或缺的。根据编码规律可以去掉序列号中的冗余信息,留下有用的信息传输。通过观察上面BS算法实例中标签的识别过程可知:命令中的碰撞位及其低位因为总是被置位为1,不包含有用的信息,这样就不要传输;标签应答的序列号最高位至碰撞位是已知的前缀信息,不包括补充信息,也不需要传输。由上面的分析可知,序列号ID中的冗余部分是不需要传输的。可以将DBS算法由双向的完整传输加以改进,只传输部分有用信息。Request命令中,读写器只需以要搜索的序列号ID的碰撞位至最高位部分为参数。所有相应位与此命令中参数相符的标签,则传输序列号的碰撞位以下部分作为应答。
2.2 DBS算法的命令
与BS算法的命令相比,DBS算法的命令做了一些改进:主要是DBS算法把第一个命令改成Request(IDn-x,X)。读写器发送参数IDn-x(ID的N-X位)给作用范围内的所有标签,相应位与IDn-x符合的标签做出响应,返回剩余的位信息。其余三条命令与前面所述BS算法一致。
2.3 DBS算法的性能分析
DBS算法与BS算法的规则相同,所以两者重复操作的过程也相同。因此,DBS算法的总搜索次数为:
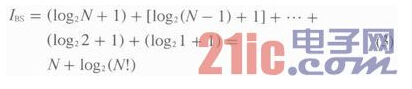
DBS算法在识别过程开始时,即算法的第一步,工作范围内的标签是需要传输整个序列号的;在这之后的识别过程中,标签只需要传输ID的有用部分位。整个识别过程平均下来,DBS的信息量只有BS算法的一半。DBS算法中,标签要传输的数据量和所需时间比起BS算法减少了近50%。
3 查询树算法(QT)
“QT(Query Tree)查询树算法基于标签ID号来分裂一组发生碰撞的标签。”在每一轮传输中,读写器向标签发送一个比特串的查询信息。读写器的一系列查询比特串记录在队列Q中。初始化队列Q为两个1位比特比特串0和1,读写器从Q中取出一个比特串,用以查询信息。若此查询信息与某标签的序列号ID的前缀信息相同,则此标签响应读写器的命令,传输自己的ID给读写器。如果读写器发送的查询比特串X1X2 X3…Xt(Xi∈{0,1},t小于标签序列号ID的长度),有多个标签同时响应读写器的查询信息,即发生了碰撞,则在此查询比特串后面增加一位,将X1X2X3…Xt0和X1X2X3…Xt1压入队列Q中。读写器下次将分别用这两个比特串作为查询信息,前面发生碰撞的标签将分为两个部分。一部分将响应查询比特串X1X2X3…Xt0,另一部分将响应查询比特串X1X2X3…Xt1。依此方法不断地增加比特串位数,直至收到响应但没有碰撞情况发生或无响应的情况,这样读写器就能够识别出所有的标签。
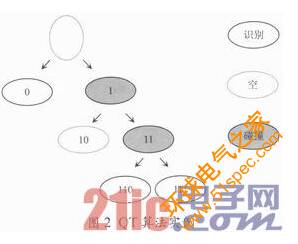
查询树算法用队列Q存储查询信息,标签不必存储序列号ID以外的无关信息,这样,标签就具有更简单的功能,可降低标签成本,因此,QT算法是无记忆的算法。图2所示是QT算法的一个示意图。系统中的标签ID号为0010、1110和1101。
4 改进型算法
4.1 改进型算法思想
读写器引入一个堆栈S来存储二又树发生碰撞时右子树节点信息,一个队列Q来存储无碰撞发生时的查询前缀。
设标签序列号ID是长为L的二进制数,读写器查询前缀是长度不大于L的二进制数。那么,读写器发送查询前缀,使其作用范围内标签将自己的序列号ID与查询前缀相比较。如果查询前缀与标签自最高位开始的部分比特串相同,则标签回复序列号ID剩余的部分比特串给读写器。初始时,二叉树只有根节点,读写器的堆栈为空,队列Q为空。
4.2 改进型算法流程
第一步,由读写器在初始时发送查询前缀(1位的二进制数“0”),此时有以下几种情况:
(1)如果只有一个标签响应,即无碰撞发生,此时可为根节点添加左子节点(表示二进制数0),将此查询前缀“0”送入队列Q,跳转到第四步。
(2)如果有多于一个的标签响应,即发生了碰撞,此时可为根节点添加左子节点(表示二进制数0),并把0送入堆栈S;然后为节点0添加左子节点00和右子节点01。将01送入堆栈S,再跳转到第三步,以00为查询前缀。
(3)如果无标签响应,跳转到第二步。
第二步,读写器发送查询前缀(1位的二进制数“1”),此时也有如下几种情况:
(1)若有标签响应且无碰撞发生,则为根节点添加右子节点(表示二进制数1),将查询前缀“1”送入队列Q中,跳转到第四步。
(2)若有碰撞发生,则为根节点添加右子节点(表示二进制数1),并把1送人堆栈S;然后为节点1添加左子节点10和右子节点11。将11送入堆栈S,以10为查询前缀。
(3)若无标签响应,说明读写器作用范围内无标签存在或者系统可能出现故障,识别流程结束。
第三步,读写器发送查询前缀。若收到响应且无碰撞发生,则将此查询前缀送入Q;若有碰撞发生,则分别添加左子树和右子树,右子树压入堆栈S,左子树作为新的查询前缀,重复步骤第三步;如无标签响应,则从堆栈S中弹出一个元素作为查询前缀,重复第三步。
第四步,当读写器成功识别某标签,先与读写器进行通信,然后使标签进入“无声”状态,即此标签不再响应读写器的查询。从堆栈S中弹出一个元素作为查询前缀,重复第三步,直至所有的标签被识别出来。
4.3 改进型算法实例
假设系统内有四个待识别的标签,其序列号ID分别为0010、0100、1010、1101。其首次识别过程如表1所列。
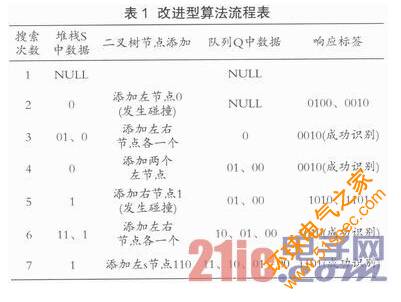
首先,读写器发送查询前缀0,标签0010和0100响应,发生碰撞,将0送入堆栈S;添加左子节电00和右子节点01,将01送入堆栈S,以00作为新的查询前缀。读写器发送查询前缀00,此时只有标签0010响应,将查询前缀00送入队列Q;此标签被成功识别,与读写器通信完毕后,进入“无声”状态。从堆栈S中弹出01,作为新的查询前缀,此时只有标签0100响应,将查询前缀01送入队列Q;此标签被成功识别。
然后再从堆栈S中弹出0,作为新的查询前缀,此时无标签响应,因此读写器以1为查询前缀。标签1010和1101响应,发生了碰撞,将1送入堆栈S;添加左子节点10和右子节点11,将11送入堆栈S,以10作为新的查询前缀。读写器发送查询前缀10,此时只有标签1010响应,将查询前缀10送入队列Q;此标签被成功识别。从堆栈S中弹出11,作为新的查询前缀,此时只有标签1101响应,将查询前缀11送入队列Q;此标签被成功识别。
最后从标签中弹出1,作为新的查询前缀,无标签响应,结束识别流程。
如上所述,通过表1中所列的首轮识别后,队列Q中的查询前缀为[00,01,10,11]。当读写器再次需要识别其作用范围内的标签时,就可直接发送队列Q中的查询前缀,这样,标签能够被快速地识别出来。
5 各种算法的Matlab仿真
下面采用Matlab下仿真系统通信量的方法来比较各个算法的效率。在识别相同标签属的前提下占用的比特数越高,则说明其通信量越大,对系统要求越高。
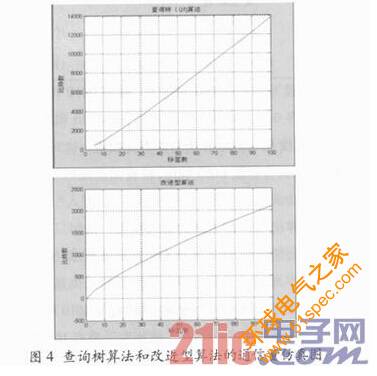
图3和图4均是在标签长度L=8的情况下所进行的仿真结果,其中图3在识别100个标签时,二进制搜索算法通信量约为7 500 b,动态二进制搜索算法通信量约为4 300 b;图4则在识别100个标签时,查询树算法在通信量约为1 3 600 b,改进型算法通信量约为2 100 b情况下的仿真结果。
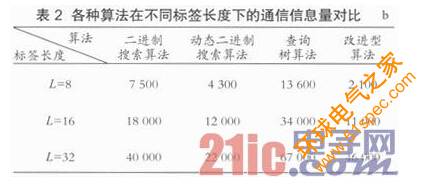
依据在标签长度为8 b时所仿真出的图3和图4所示的通信量数据,可以采用相同的仿真方法较容易地得出各种防碰撞方法在不同标签长度下的通信量数据,综合总结如表2所列。
6 结语
本文通过对RFID中各种主流防碰撞方法的思想、实现及算法的研究,提出了相应的改进型算法,并对算法进行了详细的说明。之后,对所有算法的实现进行了Matlab仿真,证实了改进型算法相较其他算法的优越性。仿真证明,在标签长度较短的情况下,该算法可以表现出极其优越的性能。但是,该算法亦有它的不足,在单个标签长度较长的情况下,该算法的通信量急剧上升。所以,在算法的通信冗余度方面还有进一步优化的必要。
下一篇: PLC、DCS、FCS三大控
上一篇: 基于14443一A协议的无


